How to host an open source LLM

This article is the result of research I conducted between April and June 2025. The focus is on solutions from the EU (and Germany in particular).
Open-source large language models (also called “open-weight” models) have emerged as viable alternatives to proprietary solutions (ChatGPT, Claude), providing organisations with more control over their AI infrastructure and data sovereignty. Leading examples include models like DeepSeek, Qwen, Llama and Mistral.
From Local Development to Production
When first exploring open-source LLMs, most developers start with tools like Ollama, which excels for local development, where you run and access the LLM on the same machine (your local computer). Ollama is perfect for experimentation and prototyping, but it’s designed for single-user, local scenarios.
What if you want to build an application that allows users to access the LLM over the internet? What happens when you need to serve hundreds or thousands of users simultaneously?
Note on terminology: I noticed people say “local” when they mean self-hosting. I use the term “local” to describe offline use on your computer, while “self-hosting” means hosting on your infrastructure with internet access. Also, this guide covers inference (querying trained models) not training or fine-tuning.
But is it good enough?
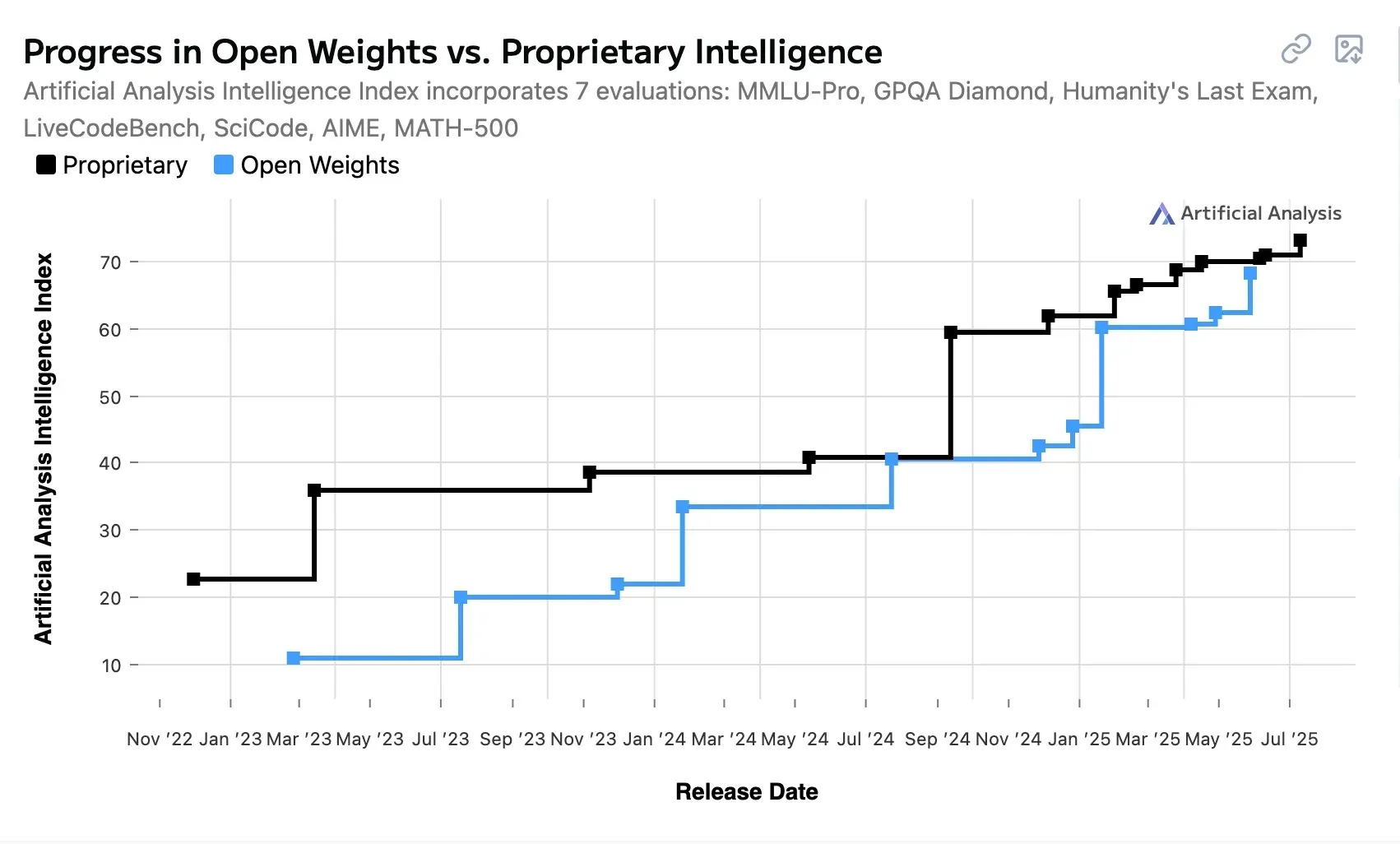
Here’s the game-changing news: open-source LLMs have dramatically closed the performance gap with proprietary models, reducing the performance difference from 8% to just 1.7% on some benchmarks. According to the Stanford HAI AI Index Report 2025, by early 2025, the gap between leading closed-weight and open-weight models had narrowed to just 1.70% on the Chatbot Arena Leaderboard.
This convergence is evident across a variety of use cases: customer support, content generation, code assistance, document analysis, and business process automation. For many practical applications, open-source models now perform at the same level as their proprietary counterparts while offering more control and potentially lower costs.
The three solutions
This article presents three solutions to run open-source LLMs that can be integrated into customer-facing applications:
Method 1: Self-hosting on your own hardware 🔧
Complete control and maximum customisation, ideal for organisations with existing infrastructure and strict compliance requirements.
Method 2: Renting a GPU from a hosting company 🚲
The sweet spot between control and convenience, offering dedicated resources without hardware management overhead.
Method 3: API Providers 💅
Providing you with an API while they handle infrastructure. This isn’t exactly “self-hosting” as promised in the title, but it’s arguably the fastest and most reliable option for getting started.
Each approach has distinct advantages, costs, and levels of complexity. Let’s examine each method in detail to help you select the most suitable approach for your needs.
Method 1: Self-Hosting on Your Own Hardware 🔧
Self-hosting gives you maximum control by purchasing and managing your own GPU infrastructure. This approach requires significant upfront investment but offers unparalleled customisation and long-term cost benefits for high-volume applications.
Hardware Options
You have several GPU options depending on your model size and performance requirements:
Professional-Grade GPUs : The Nvidia H100 remains the most popular choice in Germany and globally, offering exceptional performance for large models like Llama 70B or 405B. Expect to invest around €30,000 per card, but you’ll get enterprise-grade reliability and support.
High-End Consumer GPUs : The Nvidia RTX 6000 (approximately €7,500) provides excellent performance for mid-range models and offers a more budget-friendly entry point while still delivering professional capabilities.
Budget-Friendly Options : For smaller models like Llama 7B or Mistral 7B, the Nvidia RTX 4000 (around €1,300) can be sufficient, making this approach accessible for smaller organizations or specific use cases.
Advantages
- Complete Control: Full ownership and no vendor lock-in
- Cost Efficiency: Lower per-request costs once the hardware is amortised
- Data Security: Complete data sovereignty with no third-party access
Disadvantages
- High upfront costs: Significant investment required for hardware
- Technical complexity: Requires expertise in GPU management, model serving, and infrastructure: managing autoscaling, monitoring, security, and maintenance
Method 2: Renting GPU from a hosting company 🚲
Instead of purchasing hardware, you can rent “bare metal” GPU resources from specialised providers on an hourly or monthly basis. This approach offers the sweet spot between control and convenience, providing dedicated GPU access without the capital expenditure and technical overhead of hardware ownership.
Provider Options
RunPod.io (US)
- H200: $3.99/hour
Hetzner (Germany)
- NVIDIA RTX™ 4000 SFF Ada Generation: €219/month or €0.35/hour
- NVIDIA RTX™ 6000 Ada Generation: €967/month or €1.55/hour
IONOS (Germany)
- NVIDIA® H100/H200: €3,990/month
OVH (France)
- H100: €3.69/hour
Netcup (Germany)
- recently launched vGPU services, e.g.:
- NVIDIA H200 (vGPU): €163-€311/month
Advantages
- No hardware investment: Cheaper than self-hosting
- Reduced complexity: Less technical overhead than self-hosting
Disadvantages
- Less data sovereignty: Using other party’s infrastructure
- Higher long-term costs: More expensive than self-hosting in the long run
- Technical knowledge required: Still need expertise in model deployment and infrastructure management
- Vendor dependency: Reliant on provider availability, pricing changes, and service quality
Method 3: API Inference Providers
This is the easiest method to get started with open-source LLM hosting: API inference providers handle all the infrastructure complexity while providing simple API access to open-source models. They are also known as: LLM Providers, LLM API Providers, LLM APIs, LLM Inference Hosting, AI Model Providers, AI Model Hosting, AI Model Serving, AI Inference Platforms, or Cloud Inference APIs.
This is a rapidly growing market with many new providers entering regularly. API inference providers differ across several dimensions:
- the types of models they support
- inference speed
- pricing per token
- size of the context window
- energy consumption and green energy usage
- geographic location (important for latency but also compliance reasons)
Provider Options
This is a (non-exhaustive) list of API Inference providers and where they are based 🇪🇺 Europe or 🇺🇸 USA:
- 🇺🇸 Anyscale
- 🇺🇸 DeepInfra
- 🇺🇸 Fireworks
- 🇪🇺 GreenPT (Netherlands)
- 🇺🇸 Groq
- 🇺🇸 Hyperbolic
- 🇪🇺🇺🇸 HuggingFace (France/US)
- 🇪🇺 IONOS (Germany)
- 🇪🇺 Lemonfox.ai (Germany)
- 🇺🇸 Modal
- 🇪🇺 Nebius (Netherlands)
- 🇬🇧 Nscale
- 🇺🇸 NVIDIA NIM
- 🇺🇸 OctoAI
- 🇺🇸 OpenRouter
- 🇪🇺 OVH Cloud (France)
- 🇪🇺 Regolo.ai (Italy)
- 🇺🇸 Replicate
- 🇺🇸 Runpod
- 🇺🇸 SambaNova
- 🇪🇺 Scaleway (France)
- 🇪🇺 Stackit (Germany)
- 🇺🇸 Together.ai
Advantages
- Easy: No technical knowledge or infrastructure management required
- Immediate: Start using models within minutes of signing up
- Pay what you use: No idle cost, only pay when used
- No Maintenance: Providers handle updates, security, and infrastructure management
Disadvantages
- Less data sovereignty: Using other party’s infrastructure: Data passes through third-party systems with varying privacy policies. Here you need to check: What are their logging policies? Do they train on your data? Do they share data with another party? In the EU: Is it GDPR compliant?
- Ongoing Costs: Pay-per-use pricing can become expensive for high-volume applications
👉 A useful website to compare these providers and the models they host: https://artificialanalysis.ai/
What’s the best solution for me?
Here’s a quick decision guide:
- API Providers: Best for rapid prototyping with minimal technical overhead; choose if data sovereignty is not a priority.
- GPU Rental: Ideal for medium-scale applications with predictable traffic where you need more control than APIs but less complexity than self-hosting
- Self-Hosting: Optimal for high-volume applications, strict data compliance requirements, and organisations with dedicated technical expertise
Resources
- A fascinating comparison with the situation of web hosting in the 2000s by Gordon Buchan
- The website “Artificial Analysis” for comparing models and providers: